Description
Basic usage: - Launch `normcap` - Select a region on the screen - Retrieve recognized text in clipboard
normcap alternatives and similar packages
Based on the "OCR" category.
Alternatively, view normcap alternatives based on common mentions on social networks and blogs.
-
Signalum
To explore creating an application that detects available connections at once from wifi and bluetooth
WorkOS - The modern identity platform for B2B SaaS


* Code Quality Rankings and insights are calculated and provided by Lumnify.
They vary from L1 to L5 with "L5" being the highest.
Do you think we are missing an alternative of normcap or a related project?


README
<!-- markdownlint-disable MD013 MD026 MD033 -->
NormCap
OCR powered screen-capture tool to capture information instead of images.
![]()
![]()
![]()
Links: Repo | PyPi | Releases | Changelog | FAQs
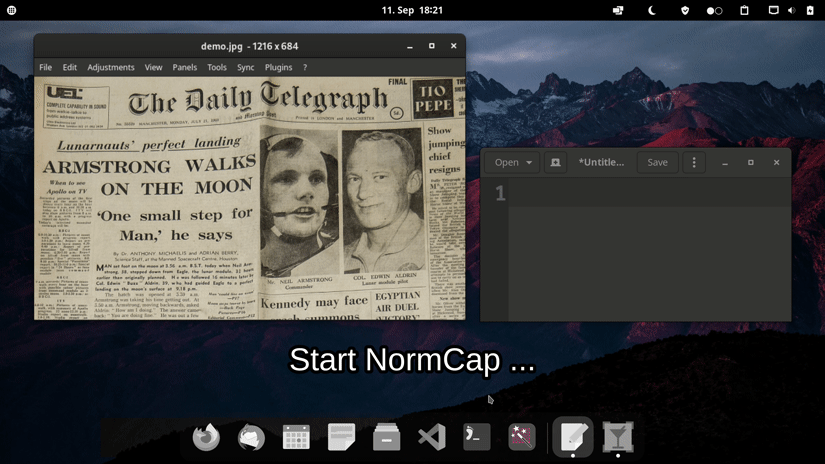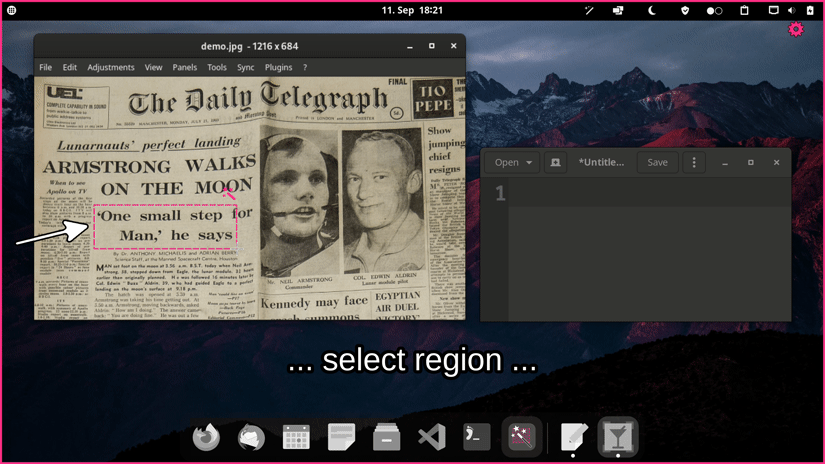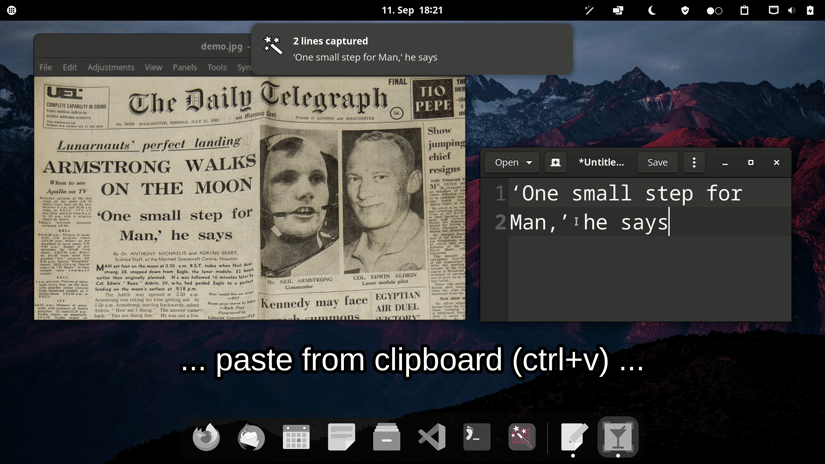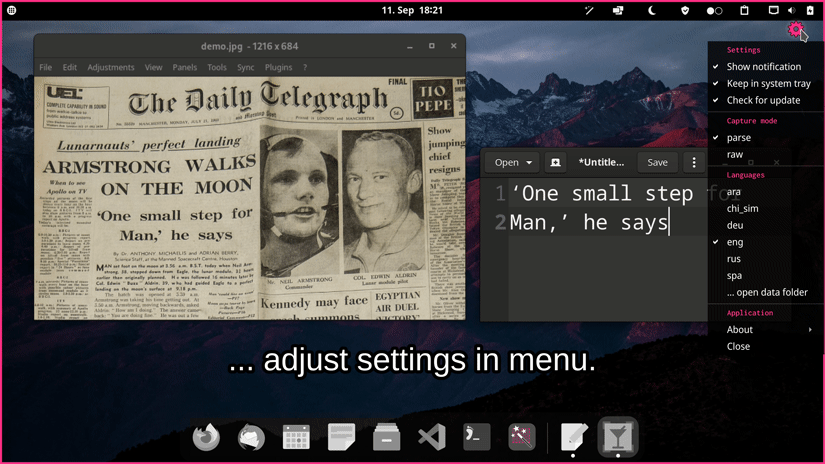
Quickstart
Install a prebuilt release:
- Windows: NormCap-0.3.15-x86_64-Windows.msi
- Linux: NormCap-0.3.15-x86_64.AppImage
- macOS: NormCap-0.3.15-x86_64-macOS.dmg \ (On macOS, allow the unsigned application on first start: "System Preferences" → "Security & Privacy" → "General" → "Open anyway". You might also need to allow NormCap to take screenshots. Background: #135)
Install from repositories:
- Arch / Manjaro: Install the
normcappackage from AUR. - FlatPak (Linux): Install com.github.dynobo.normcap from FlatHub.
If you experience issues please look at the FAQs or open an issue.
Python package
As an alternative to a prebuilt package you can install the NormCap Python package for Python >=3.9:
On Linux
# Install dependencies (Ubuntu/Debian)
sudo apt install build-essential tesseract-ocr tesseract-ocr-eng libtesseract-dev libleptonica-dev wl-clipboard
## Install dependencies (Arch)
sudo pacman -S tesseract tesseract-data-eng wl-clipboard
## Install dependencies (Fedora)
sudo dnf install tesseract wl-clipboard
## Install dependencies (openSUSE)
sudo zypper install python3-devel tesseract-ocr tesseract-ocr-devel wl-clipboard
# Install normcap
pip install normcap
# Run
./normcap
On macOS
# Install dependencies
brew install tesseract tesseract-lang
# Install normcap
pip install normcap
# Run
./normcap
On Windows
1. Install Tesseract 5 by using the
installer provided by UB Mannheim.
2. Adjust environment variables:
- Create an environment variable
TESSDATA_PREFIXand set it to Tesseract's data folder, e.g.:
setx TESSDATA_PREFIX "C:\Program Files\Tesseract-OCR\tessdata"
- Append Tesseract's location to the environment variable
Path, e.g.:
setx Path "%Path%;C:\Program Files\Tesseract-OCR"
- Make sure to close and reopen your current terminal window to apply the new variables. Test it by running:
tesseract --list-langs
3. Install and run NormCap:
# Install normcap
pip install normcap
# Run
normcap
Why "NormCap"?
See XKCD:

Development
Prerequisites for setting up a development environment are: Python >=3.9, Poetry>=1.2.0b2 and Tesseract (incl. language data).
# Clone repository
git clone https://github.com/dynobo/normcap.git
# Change into project directory
cd normcap
# Create virtual env and install dependencies
poetry install
# Register pre-commit hook
poetry run pre-commit install
# Run NormCap in virtual env
poetry run python -m normcap
Credits
This project uses the following non-standard libraries:
- pyside6 - bindings for Qt UI Framework
- pytesseract - wrapper for tesseract's API
- jeepney - DBUS client
And it depends on external software:
- tesseract - OCR engine
- wl-clipboard - Wayland clipboard utilities
Packaging is done with:
- briefcase - converting Python projects into standalone apps
Thanks to the maintainers of those nice tools!
Similar open source tools
If NormCap doesn't fit your needs, try those alternatives (no particular order):
- TextSnatcher (Linux)
- GreenShot (Linux, macOS)
- TextShot (Windows)
- gImageReader (Linux, Windows)
- Capture2Text (Windows)
- Frog (Linux)
- Textinator (macOS)
Certification
![]()
*Note that all licence references and agreements mentioned in the normcap README section above
are relevant to that project's source code only.